Mbox Analysis
About this dataset
This dataset is a dump of all posts sent on all mailing lists hosted at the Eclipse Forge. Although this is public data (the mailing lists can be browsed on the official mailman page) all data has been anonymised to prevent any misuse. The privacy issues identified, along with the anonymisation process, have been covered in a dedicated document.
These files are published under the Creative Commons BY-Attribution-Share Alike 4.0 (International) licence.
The dataset is composed of two parts:
- eclipse_mls_full.csv contains an extract of all the messages exchanged on the various mailing lists. The present document uses this CSV as input data.
- The full list of mboxes, one file per mailing list. They are listed in the dataset main page and can be downloaded directly from the mboxes subdirectory.
All of them are updated weekly at 2am on Sunday.
Privacy concerns
We value privacy and intend to make everything we can to prevent misuse of the dataset. If you think we failed somewhere in the process, please let us know so we can do better.
All personally identifiable information has been scrambled using the data anonymiser Perl module. As a result there is no clear email address in this dataset, nor any UUID or name. However all identical information produces the same encrypted string, which means that one can still identify identical data without knowing what it actually is. As an example email addresses are split (name, company) and encoded separately, which enables one to e.g. identify posters from the same company without knowing the company.
The anonymisation technique used basically encrypts information and then throws away the private key. Please refer to the documentation published on github for more details.
About this document
This document is a R Markdown document and is composed of both text (like this one) and dynamically computed information (mostly in the sections below) executed on the data itself. This ensures that the documentation is always synchronised with the data, and serves as a test suite for the dataset.
Basic summary
- Generated date: Sun Apr 25 05:00:18 2021
- First date: 2001-11-05 19:14:58
- Last date: 2021-04-24 19:14:44
- Number of posts: 682977
- Number of attributes: 7
Structure of data
This dataset is composed of a single big CSV file. Attributes are: list, messageid, subject, sent_at, sender_name, sender_addr.
Examples are provided at the end of this file to demonstrate how to use it in R.
list
- Description: The mailing list and project of the post.
- Type: String
Examples:
| Project list names |
|---|
| japan-wg |
| mobile-iwg |
| higgins-announce |
| dtp-models-dev |
| golo-dev |
messageId
- Description: A unique identifier for the post.
- Type: String (Scrambled Base64)
Examples:
| Message ID |
|---|
| AjPUDrPsvxAjpglR@QssNypKbbV2bqh4K |
| pCPSBux76e/zIk0Y@KbhFGZBrAY0Yu6oT |
| dWn4txaTMEF4hpul@dg3joli2vA2kIOnL |
| br9scKGglklMFx4U@Ku1ApkgX1l1loldC |
| BzOnbp1U+Ir3QmAA@G+edXxEtJuTpS30I |
Subject
- Description: The subject of the post as sent on the mailing list.
- Type: String
Examples:
| Subject |
|---|
| \[wtp-dev\] Web Services Webinar May 3 |
| \[wildwebdeveloper-dev\] Wild Web Developer 0.11.0 is released! |
| \[iot-wg\] Launching Open IoT Challenge 4.0 |
| \[geclipse-dev\] \[luntbuild\] build of “gEclipse/NightlyBuild/geclipse-1.0\_N20090416-0500” failed |
| \[emfcompare-build\] \[Hudson\] Build failed in Hudson: master-performance-large-git \#623 |
Sent at
- Description: The time of sending for the post.
- Type: Date (ISO 8601)
Main characteristics:
- First date: 2001-11-05 19:14:58
- Last date: 2021-04-24 19:14:44
Examples:
| Sent date |
|---|
| 2016-10-25 20:08:00 |
| 2014-04-29 19:52:23 |
| 2004-05-28 22:56:07 |
| 2017-10-11 14:49:11 |
| 2018-04-23 07:33:14 |
Sender name
- Description: The name of the sender of the post.
- Type: String (Scrambled Base64)
- Number of unique entries: 24313
Examples:
| Sender names |
|---|
| hn+wxp7VMEWXNNpy |
| vfMPmEG1KoXYz/Q5 |
| Dr55ScXXtZET8iQi |
| ejvmpyY7+CPEdn2m |
| EjerGCoSH5j+2GM7 |
Note: A single name repeated several times will always result in the same scrambled ID. This way it is possible to identify same-author posts without actually knowing the name of the sender.
Sender address
- Description: The email address of the sender, encoded.
- Type: String (Scrambled Base64)
- Number of unique entries: 24660
Examples:
| Sender addresses |
|---|
| bjj4k7C2yBuwGGyy@RjQNvgRmrv9gbXL6 |
| plZAZz89mDfA3YM0@KbhFGZBrAY0Yu6oT |
| untw1HPG26ZrjqWg@CB0xIM87IAyZypaK |
| FAVevB8a6RZZJ0Xm@Cf0Yxjkx5k0d0UsN |
| sd7N4GN0XrnPq/4E@KbhFGZBrAY0Yu6oT |
Note: A single email address repeated several times will always result in the same scrambled email address. Furthermore both parts of the email (name, company) are individually scrambled, which means that one can identify email addresses from the same company without actually knowing the real company or name of the sender.
Using the dataset
Reading CSV file
Reading file from eclipse_mls_full.csv.
project.csv <- read.csv(file.in, header=T)
We add a column for the Company, which we extract from the email address (i.e. the domain name):
project.csv$Company <- substr(x = project.csv$sender_addr, 18, 33)
Number of columns in this dataset:
ncol(project.csv)
## [1] 7
Number of entries in this dataset:
nrow(project.csv)
## [1] 682977
Names of columns:
names(project.csv)
## [1] "list" "messageid" "subject" "sent_at" "sender_name"
## [6] "sender_addr" "Company"
Using time series (xts)
The dataset needs to be converted to a xts object. We can use the sent_at attribute as a time index.
require(xts)
project.xts <- xts(x = project.csv, order.by = parse_iso_8601(project.csv$sent_at))
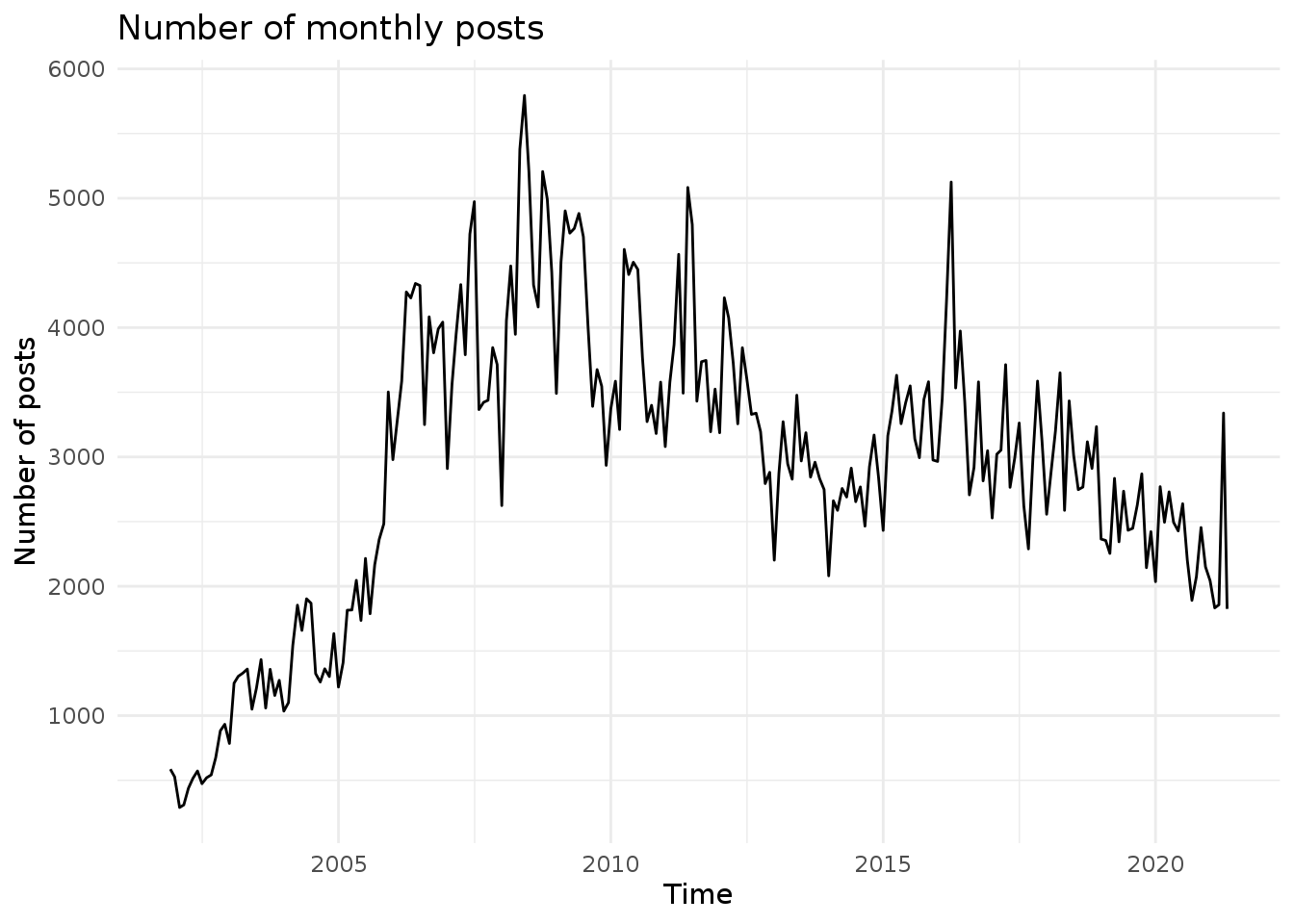
Plotting number of monthly posts
When considering the timeline of the dataset, it can be misleading when there several submissions on a short period of time, compared to sparse time ranges. We’ll use the apply.monthly function from xts to normalise the total number of monthly submissions.
project.monthly <- apply.monthly(x=project.xts$sent_at, FUN=nrow)
autoplot(project.monthly, geom='line') +
theme_minimal() + ylab("Number of posts") + xlab("Time") + ggtitle("Number of monthly posts")
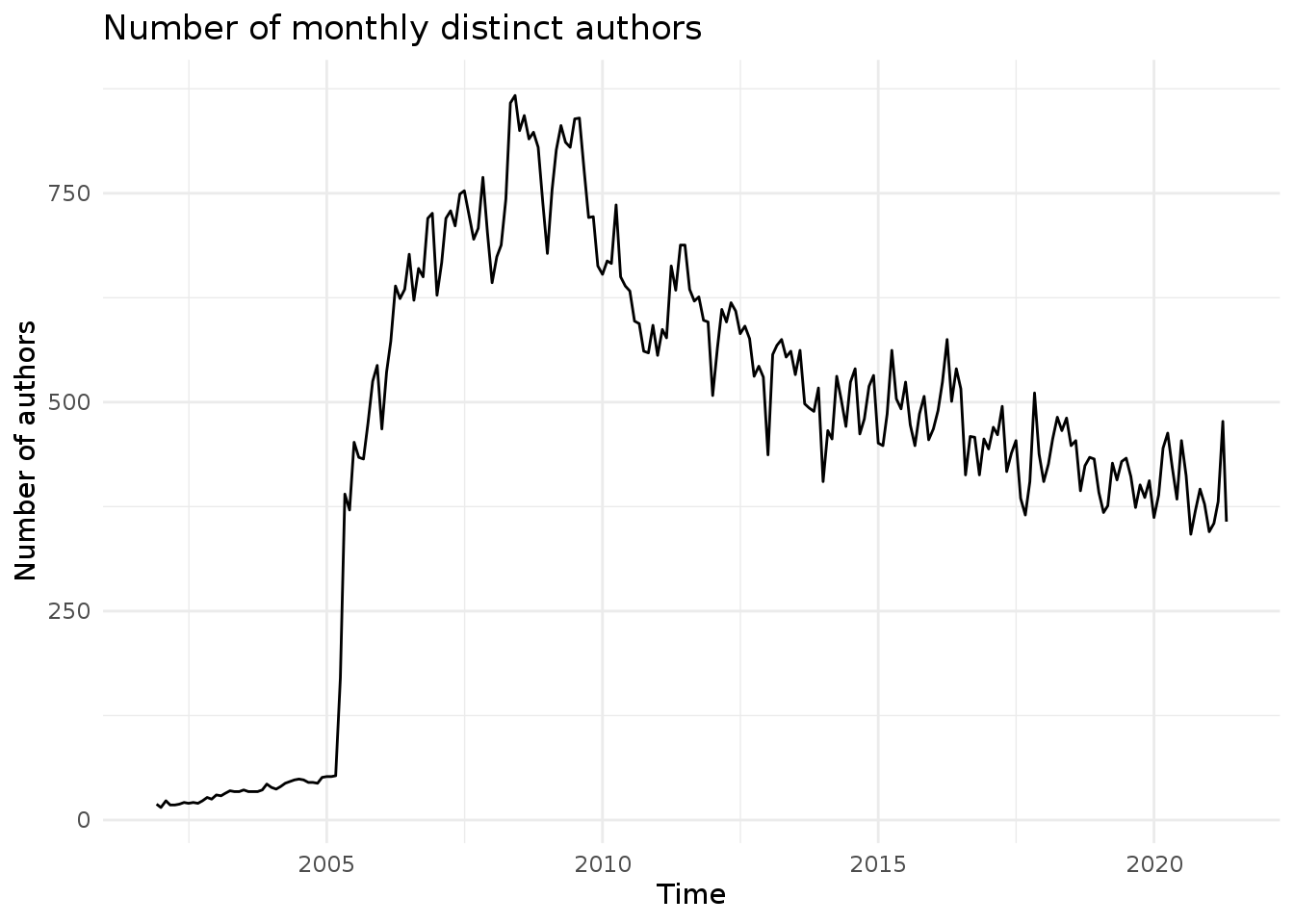
Plotting number of monthly reporters
One author can post several emails on the mailing list. Let’s plot the monthly number of distinct authors on the mailing list. For this we need to count the number of unique occurrences of the email address (attribute sender_attr).
count_unique <- function(x) { length(unique(x)) }
project.monthly <- apply.monthly(x=project.xts$sender_addr, FUN=count_unique)
autoplot(project.monthly, geom='line') +
theme_minimal() + ylab("Number of authors") + xlab("Time") + ggtitle("Number of monthly distinct authors")
Plotting activity of authors
We want to plot the number of emails sent by each author regardless of the mailing list they were sent on. We display only the 10 top posters:
| Sender address | Number of posts | Company |
|---|---|---|
| WTXwUNMqdlSw+t3X@CB0xIM87IAyZypaK | 38007 | CB0xIM87IAyZypaK |
| E6Vucc1L0x0Dy0j/(**CB0xIM87IAyZypaK?**) | 19933 | CB0xIM87IAyZypaK |
| JWrJ5MKbaSoIj7fA@CB0xIM87IAyZypaK | 15720 | CB0xIM87IAyZypaK |
| XzFnxoGpIIiDmdu4@CB0xIM87IAyZypaK | 9845 | CB0xIM87IAyZypaK |
| untw1HPG26ZrjqWg@CB0xIM87IAyZypaK | 8828 | CB0xIM87IAyZypaK |
| vru1ZcDQpkVchkhA@giWiTkBFolJCWi6m | 8428 | giWiTkBFolJCWi6m |
| cuVf7KfGri/UGYF/(**CB0xIM87IAyZypaK?**) | 6969 | CB0xIM87IAyZypaK |
| Xiqv7IUAtuHslb2i@CB0xIM87IAyZypaK | 5327 | CB0xIM87IAyZypaK |
| Wr0bTpweI8ce3WtM@CB0xIM87IAyZypaK | 5012 | CB0xIM87IAyZypaK |
| qB0Ny51NVuBp3p8n@KbhFGZBrAY0Yu6oT | 4945 | KbhFGZBrAY0Yu6oT |
Now plot these 50 top posters with ggplot and use the company (i.e. second part of the email address) for the colour:
authors.subset <- head( authors, n = n)
authors.subset.df <- as.data.frame(authors.subset)
names(authors.subset.df) <- c('ID', 'Posts')
authors.subset.df$Author <- substr(x = authors.subset.df$ID, 1, 16)
authors.subset.df$Company <- substr(x = authors.subset.df$ID, 18, 33)
p <- ggplot(data=authors.subset.df, aes(x=reorder(Author, -Posts), y = Posts, fill = Company)) +
geom_bar(stat="identity") +
theme_minimal() + ylab("Number of posts") + xlab('Posters') +
ggtitle(paste(n, " overall top posters on Eclipse mailing lists", sep="")) +
theme( axis.text.x = element_text(angle=60, size = 7, hjust = 1))
g <- ggplotly(p)
g
#api_create(g, filename = "r-eclipse_mls_authors")
Posts by Company
We want to know what companies posted the most messages in mailing listsacross years. To that end we select the 20 companies that have the larger number of posts and plot the number of messages by company year after year.
comps_list <- head( sort( x = table(project.csv$Company), decreasing = T ), n=20 )
df <- data.frame(Company=character(),
Year=character(),
Posts=integer(),
stringsAsFactors=FALSE)
for (i in seq_along(1:20)) {
project.comp.xts <- project.xts[project.xts$Company == names(comps_list)[[i]],]
project.comp.yearly <- apply.yearly(x=project.comp.xts$Company, FUN=nrow)
for (j in seq_along(1:nrow(project.comp.yearly))) {
year <- format(index(project.comp.yearly)[[j]],"%Y")
comp <- as.data.frame(t(c(names(comps_list)[[i]], year, as.integer(project.comp.yearly[[j]]))))
names(comp) <- c("Company", "Year", "Posts")
df <- rbind(df, comp)
}
}
df$Company <- as.character(df$Company)
df <- df[order(df$Company),]
p <- ggplot(data=df, aes(x=Year, y = Posts, fill = Company)) + geom_bar(stat="identity") +
theme_minimal() + ylab("Number of posts") + xlab('Years') +
ggtitle("Top 20 Companies involved in Eclipse mailing lists across years") +
theme( axis.text.x = element_text(angle=60, size = 7, hjust = 1))
g <- ggplotly(p)
g
#api_create(g, filename = "r-eclipse_mls_companies")